Building a Robust Performance Monitoring Strategy for your IP/MPLS Core Network

Communication service providers (CSPs) operating large IP/MPLS core networks are faced with the challenge of building and operating networks that should work 24×7. Connectivity over data networks is a critical foundation today for all business and social interactions and operations. More and more critical traffic is carried over these networks as business automate operations and migrate their compute resources and operations into the cloud.
Service providers are experts on building networks that are resilient. Regardless, there are still too many incidents when a service provider network is down and impacting a significant amount of consumer and business services. Solving and fixing the problem may take anything from minutes to hours or in worst case even days. It is not uncommon that the issues are first reported by the customers.
However, services are not only disrupted by network outages. The service may be degraded although the network is up in the traditional sense. Too much quality impacts on the traffic on the network can cause services to stop functioning well and may in some cases totally interrupt the service. In fact, many business users experience shorter a few minute-long performance degradations every day and service providers are typically not even aware of these degradations. Hence, they have no way of fixing the issues, which obviously leads to weakened user experience and customer satisfaction.
In order to take care of their customers digital experience on their network, service providers need to get visibility into their network performance for all users and services. To stay on the pulse of their networks, the CSPs need tools that provide:
- Granular and accurate active monitoring of all service classes
- Effective troubleshooting tools to identify issues in minutes rather than hours or days
- Pro-active monitoring to identify issues before they affect end-users
On-demand Carrier and Core Network Assurance webinar
Get a full on experience. Check it out now ->
Granular and Accurate Active Monitoring for all Service Classes
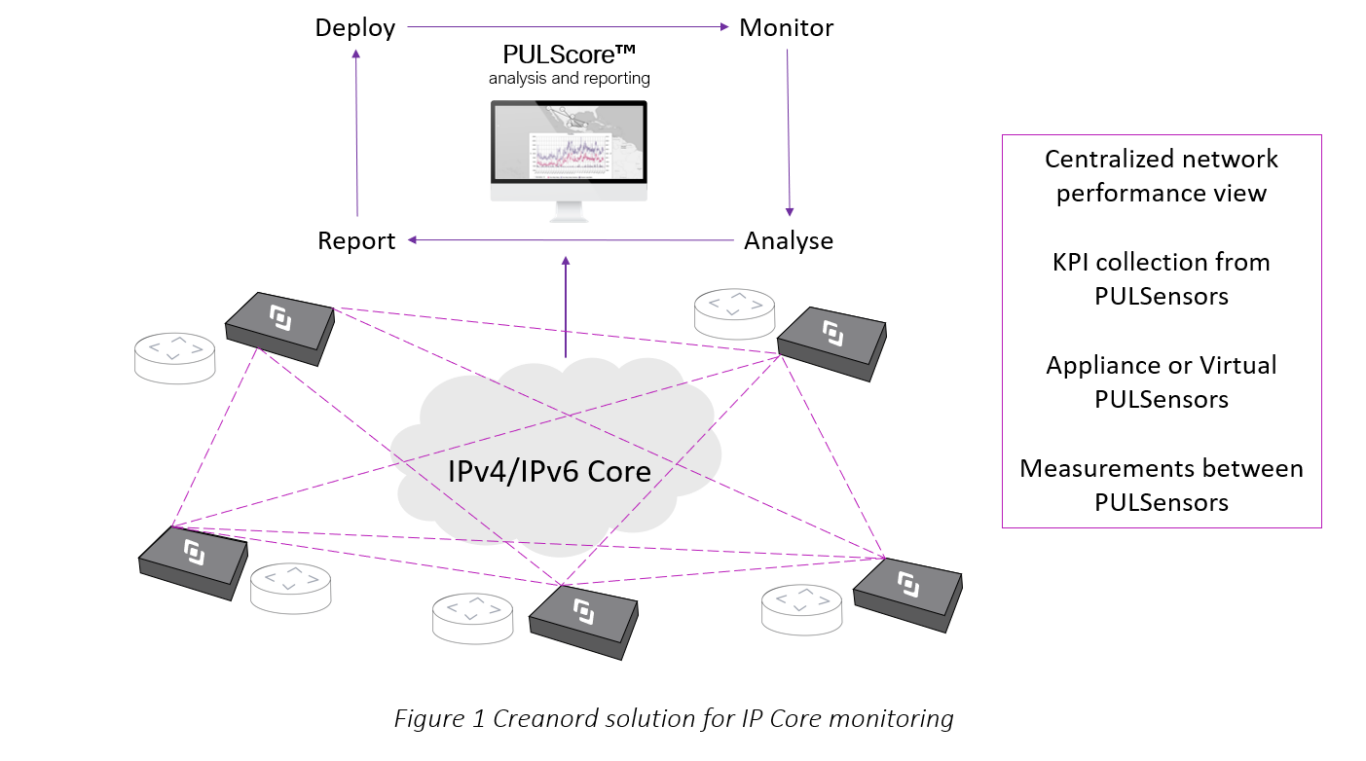
Core network performance should be monitored and measured using KPIs that have a direct impact to the success of delivered services. These KPIs are latency, jitter and packet loss. In the IP/MPLS core, the most feasible option to monitor the network is based on the active measurement technology, which scales cost-efficiently and enables full visibility to the network at granular levels regardless of what live traffic the network carries. In active measurement the actual services are simulated by injecting test traffic into the network. The performance of this traffic delivery can be then measured and monitored, which gives a great indication of the performance of any similar traffic transported between the measurement points. In order to detect the possible performance impairments in the core network, the packet generation in the active testing solution must be accurately timestamped, even at the microsecond level. Test traffic must be sent with adequate, sometimes even at millisecond frequency and all service classes need to be monitored. This is the only way to truly detect issues, which are related to the bursty nature of the network traffic. These are also the issues which often remain hidden. When service provider gains this accurate visibility to their network, they can truly react to issues early based on their severity before they become customer reported problems.
Effective troubleshooting tools to identify issues in minutes rather than hours or days
However, collecting all the data at granular levels is only getting you so far. You have a lot of measurements and data from your network, but you still need to find out if something is wrong in the network and why. To be effective in this process, the active testing tools must be able to process all the collected data, apply analytics and machine learning and present the data in a format that allows the user to identify when something is wrong in the network and to quickly find the root-cause with intuitive reports, graphs and events. This way the service provider can minimise the time spent on understanding the issue, its impact to services and the use of resources when taking corrective actions.
Pro-active monitoring to identify issues before they affect end-users
Since even a small impairment in a core network affects a large number of customers and services, service providers need a pro-active monitoring approach to their network so that they may fix issues in their network before they affect the end users. Monitoring tools are needed that can report on trends and anomalies in the network as well as early indications of bottlenecks. Knowing in advance where you need to add capacity, change routing policies or re-engineer your network provides you with sufficient time to implement the changes before the performance has degraded to the point that end-users become affected.
To learn more about how Tier-1 service providers build modern monitoring capabilities, read the case study: “Solution to guarantee performance in global Tier-1 service provider carriers’ carrier services”. For general information about core network monitoring, please check out the solution brief “Solution for IP core monitoring”.
About Creanord
Creanord is a specialist in service assurance with more than 20 years of experience in developing solutions for network service providers. Creanord’s service assurance solutions enable accurate tracking of network and application quality and performance and the technology has been implemented in over 30 countries and more than 60 networks globally.
Contact us to find out more on how we can help you build outperforming networks.
On-demand Carrier and Core Network Assurance webinar
Get a full on experience. Check it out now ->