Symbiotic Network Service Assurance by combining Passive & Active Monitoring Techniques

1. Background
In several surveys the great majority of the operators are saying that brand new revenue streams, mainly from enterprise, would be critical to their 5G business case. However, achieving those new revenues will depend on deploying 5G in a new way – the investments cannot be only on data speeds, but need to focus on 5G’s most important differentiators. Foremost among these is the ability to support ultra-reliable low latency communications (URLLC), which will enable entirely new applications especially for enterprises. By guaranteeing an extremely rapid response to data requests and enabling mission-critical reliability and SLAs, 5G will open up many high value use cases for enterprises and operators.
Additionally, the network is moving to the cloud, the mobile network functions are now virtualized and are being deployed anywhere from centralized data centers to the multi-access edge computing (MEC) devices. Networks are also significantly more dynamic than before those are constantly changing. Thus, manual and traditional reactive network management won’t be able to guarantee the required network and service quality for the next-gen services. Therefore, to support most of these use cases will require more than just deploying a 5G network that conforms to the latest 3GPP specifications. This will require new ways how to manage the quality; service providers will need to have new tools to stay on top of network issues. Service providers need to have capabilities to quickly isolate root causes of end-to-end issues (which many times are invisible) and avoid major network outages.
In order to enable “5 nines” or in certain use-cases even “6 nines” network availability service providers need a full picture of the network. With other words it means implementing all possible network quality monitoring capabilities.
There are two well-accepted methods of monitoring network and service performance; active and passive, and each comes with its own strengths. In conclusion, service providers shouldn’t investigate whether active or passive monitoring is needed, in the modern networks both are needed.
2. Network Monitoring Techniques
A short explanation about different network monitoring techniques.
Passive monitoring: This is the traditional technique to monitor and analyze the health of the network. Passive monitoring means analyzing live network traffic, at a specific point in the network – for example at its simplest, passive monitoring may be nothing more than the periodic collecting of port statistics, like byte and packet transmit and receive numbers. However, in the modern deployments passive monitoring includes capturing live traffic flowing through a port for detailed, non-real-time, analysis of things like signaling protocols, application usage or top bandwidth consumers. Typically, the traffic is captured directly from the actual network element or via a specific passive probe.
Picture 1: Examples of different use cases for passive monitoring
Active monitoring: This is also called as synthetic monitoring. It means injecting test traffic into the network, typically with the same forwarding criteria as the user traffic (service) being monitored, and then measuring its performance. Active monitoring emulates real network element traffic, network devices and end-users. Active monitoring tests can be either “one-way tests” or round trip based. As mentioned, the active monitoring emulates the actual live traffic, it is ideal to provide a real-time view of the end-to-end performance with regards to latency, jitter and packet loss. Also, additional KPIs can be retrieved, especially when user-experience KPIs are being measured. Active testing can be performed between any two sites along the same end-to-end service path; thus, it will be possible to calculate the quality of the individual network segments which will provide a real-time visibility where the potential issues are actually located.
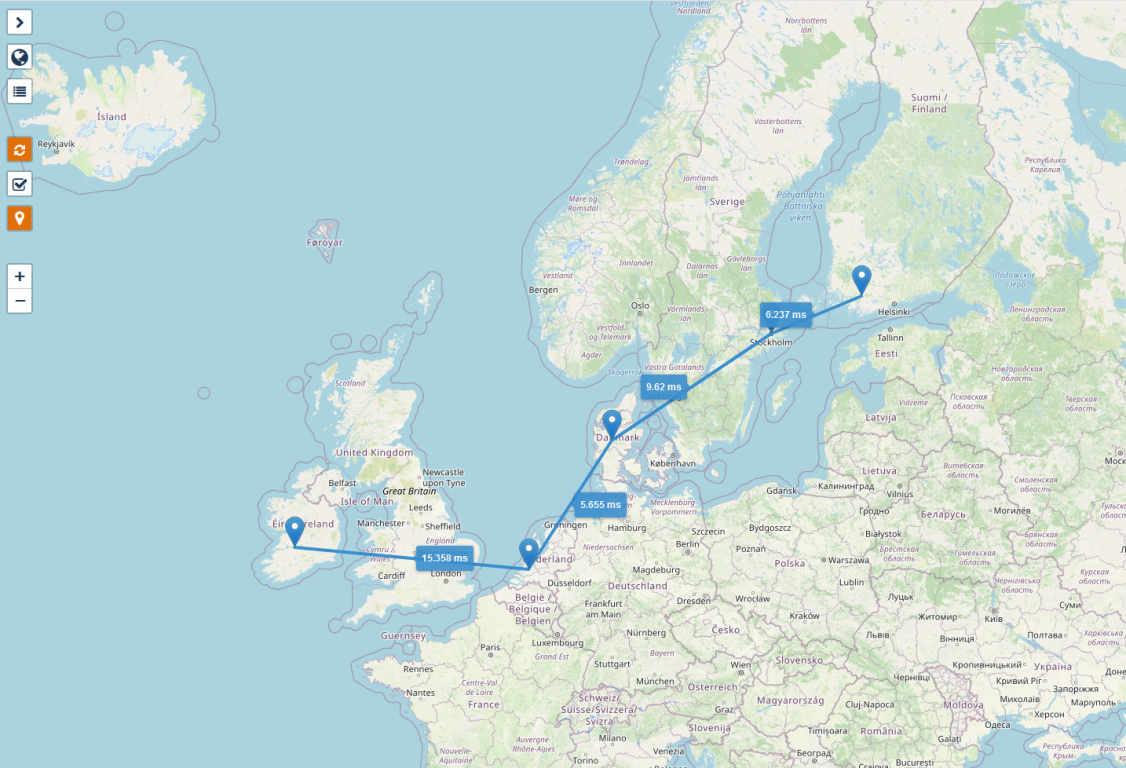
Picture 2: Network Segmentation with active testing.
Many service providers are also concerned of using active monitoring since it’s assumed to significantly increase the load of the network. The truth is that the bandwidth added by active testing is negligible in today’s networks. For instance, with a test interval of 1 second, which provide good visibility into the network performance, the bandwidth consumed by a TWAMP test is roughly 0,5 kbit/s (a TWAMP packet together with UDP and IP headers is roughly 70 bytes). So, in a 1G/10G/100G/400G links this is totally negligible.
3. Pros & Cons of using passive & active monitoring
As we already know, passive monitoring is well suited for in traffic and protocol analysis including signaling data or application-level analysis detecting issues that affect large part of the network. However, passive monitoring has certain shortcomings. As the name suggests, it’s “passive”, the customers do have to use the network and services first, traffic needs to be available before it can be monitored and analyzed passively. So just to summarize the main challenges with passive monitoring are:
- Requires network data i.e., can be used when the network has been up and running, not designed for turn-up and service activation testing when real network data isn’t available yet.
- Not designed for immediate troubleshooting and proactive network monitoring.
- Since passive monitoring is depended on retrieving data from physical elements or from specific passive probes, it is also expensive to use this technology for many end-to-end applications. As an example, passive monitoring isn’t commercially feasible solution to monitor the latency of a large mobile network including thousands, sometimes tens of thousands of base stations and routers.
However, active monitoring fills these gaps. It enables:
- Turn-up testing before live traffic data is available.
- Immediate and proactive network troubleshooting.
- Identifying minor issues before they become major.
- Immediate data insights and information for decision-making – this is an important capability in the self-healing and adaptive network applications.
Active monitoring is typically the primary method for policing SLAs, since it provides a real-time view of performance.
Additionally, active monitoring is a cost-effective option for many network-wide deployments, accurate latency measurements for a large number of end-points being a good example. Monitoring the latency of a large mobile network requires only a small number of active measurement probes/agents/sensors, thus the deployment can be done quickly and cost-effectively.

Picture 3: Symbiotic network service assurance.
4. Assuring the services throughout the service lifecycle
Service providers should not be forced to pick between active and passive monitoring. Active and passive monitoring are both important in their own way and can provide valuable insights on the network performance. Active monitors generate predictive data to warn of potential network issues and maintain the real-time visibility. Additionally, it can be used to validate the service SLAs in turn-up/service activation. Passive monitors show you the different perspective using real performance data, understanding the used bandwidth, application usage and signaling performance. For more information see the picture 4. how to maximize the quality throughout the service lifecycle.
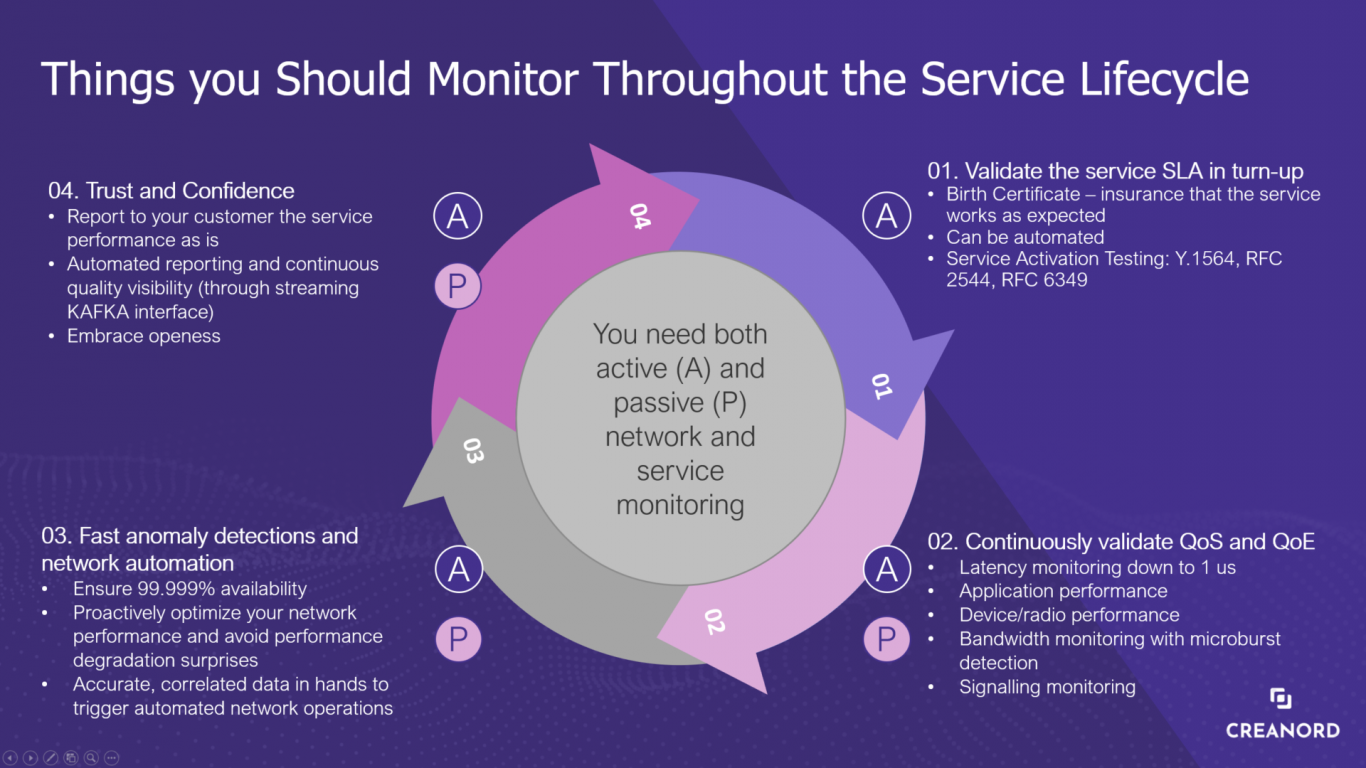
Picture 4: Service Lifecycle Assurance
Conclusion, using a combination of both active and passive monitoring is the best way to monitor and maximize the network performance throughout the service lifecycle.